
�������: 1-15 ���鵽�����ƿ�ѧ�뼼�� ǿ��ѧϰ����ؼ�¼23�� . ��ѯʱ��(0.24 ��)
���ڹ���ʱ��ǿ��ѧϰ�����ܳ�����������㷨
����ʱ�� ǿ��ѧϰ �������� �������
<
2024/1/16
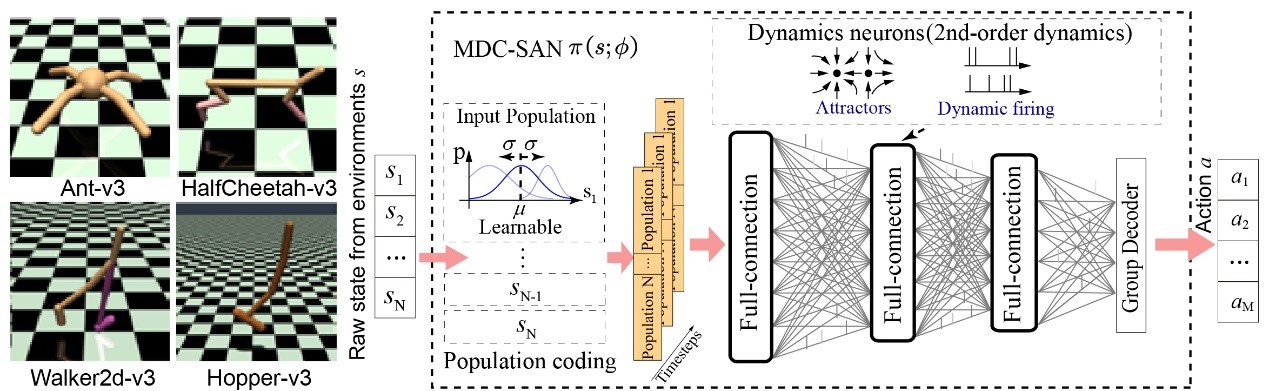
������ܳ����ĸ߾��Ȳ����������,���һ�ֻ��ڹ���ʱ��ǿ��ѧϰ(Receding horizon reinforcement learning,RHRL)�IJ�����Ʒ���.�����IJ����������ǰ���ͷ��������ֹ���,ǰ���������ɲο�·���������Լ�����ѧģ��ֱ�Ӽ���ó�;������������ͨ�����ù���ʱ��ǿ��ѧϰ�㷨������Ÿ��ٿ�������õ���

���߽����ǿ��ѧϰ������Ӧ�����ֻ�˳���ٿ���ͼ��
�㷨Ӧ�� ��ͨ�źſ��� ����ϵͳ
<
2023/5/22
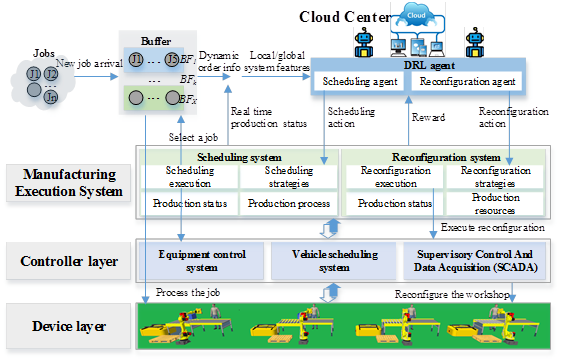
2023��1��5-6�գ����߽����ǿ��ѧϰ������Ӧ�����ֻ�˳�����С���۽����ǿ��ѧϰ��DRL���벩�ġ��Զ���ʻ�ͻ����˵ȷ����ǰ�ؽ�չ�����³ɹ���չ���ֽ�����������4λ����ר�ҷֱ�ӡ�С����ǿ��ѧϰ�㷨��Ӧ�õ��о���չ�������������ǿ��ѧϰ�Ľ�ͨ�źſ��ƽ�չ����������ϵͳ�ֲ�ʽЭͬ���ơ������������ǿ��ѧϰ�����ܵ�������Դ��Ч���á��Ȳ�ͬ��������˾��ʷ��������滷��������ƽ̨����ͬ��ֱ��������...
�й���ѧԺ�Զ����о������������о�����ͨ����߶ȶ�̬����������������ʵ�ָ�Чǿ��ѧϰ��ͼ��
��������� �������������� ��߶ȶ�̬����
<
2022/3/4
����������� (Deep Neural Network��DNN) �İ����£����ǿ��ѧϰ�����ิ��������ȡ���˾�ɹ�������Ϸ������˿��Ƶȡ�Ȼ�������ǿ��ѧϰ��ʽ����֪������ǿ��ѧϰ��ʽ��Ȼ�����Զ���������и��������Ⱥ�������и��Ӷ���ѧ��������Ԫ�����룬�����þ�����������Ŀ�����ѧϰ��������һ���γɸ��ӵ���֪���ܡ����ڣ��Զ��������������о������첨���������Ŷӣ�ͨ��������ϵͳ�ж�߶���Ϣ...
�й���ѧԺ�����Զ����о����ڻ������ǿ��ѧϰ�ij������ܵ��ȷ����о�ȡ���½�չ��ͼ��
���ǿ��ѧϰ ������� �������� ״̬�ռ� ��Ϊ�ռ�
<
2022/4/29
2021��10�£��й���ѧԺ�����Զ����о����ڳ������ܵ��ȷ����о�ȡ���½�չ���������ǿ��ѧϰ����ʵ���˶�̬�����¿��ع�����Զ�̬�������Ⱥͳ����ع���ʵʱ�Ż������ܾ��ߣ��о��ɹ�������International Journal of Production Research�����ڳ����������������NP�����⣬��ͳԪ����ʽ�㷨ֻ���ڶ���ʽʱ������ý��Ž⡣�Դ��ģ���⣬Ԫ����ʽ�㷨�����ʱ����������...
Ϊ�������˫�������б�²����ȶ���,���������һ�ֻ������ǿ��ѧϰ������˫������˲�̬���Ʒ���.ͨ����������˫������˵Ļ�϶���ѧģ�����ȶ����߹���,������״̬�ռ䡢�����ռ䡢episode�����뽱������.�����û���DDPG�Ľ���Ape-X DPG�㷨����ѧϰ��,����˫����������ڽϴ�б�·�Χ��ʵ���ȶ�����.����ʵ�����,Ape-X DPG������ѧϰ�������������ٶȾ����ڻ���PER��DDP...

�й���ѧԺ�Զ����о������ǿ��ѧϰ�Ŷ�����������ǿ��ѧϰ��δ֪��������̽��������ͼ��
�й���ѧԺ�Զ����о��� ���ǿ��ѧϰ δ֪���� ����̽������
<
2020/8/24
�п�Ժ�Զ��������ǿ��ѧϰ�Ŷ������һ�ֻ������ǿ��ѧϰ��δ֪��������̽���㷨���ܹ�ʹ��������û������Ļ���������̽������ʵʱ����������ͼ�����ķ�����2020��IEEE TNNLS��[1]��δ֪����̽����ָ��������û���κ�����֪ʶ������£���һ���µĻ�����ͨ���ƶ�����������������ͼ�Ĺ��̣���ӳ�˻�����ϵͳ���������������ͶԻ�������Ӧ�ԣ��ǻ����������һ���ȵ����⡣����ʵ�������Ź㷺��Ӧ�ó��������...
Ϊʵ����������������˵�������̬���������һ�ֻ���ģ��ǿ��ѧϰ�ı䵼���˻�������ģ�ͣ�ͨ������ѧϰ�ķ�ʽ���˵IJ������Կ��ǵ��˻�����������֮�У����ܹ�����Ӧ�ص������ɿ���ģ������Ӧ�����ߵĿ�����ͼ��ͨ���������Ƶ��������������������������ص�ʵ����֤��ʵ������������ģ��Sarsa (��)ѧϰ�ı䵼�ɿ���ģ�Ϳ�ʵ����˳��Ȼ�Ļ�е�۰�λ�������ܹ����������������и��ε�����仯�����нϸߵĿ�...
2017���й���ý�������ý����Ϣ�����е����ǿ��ѧϰ��ר�����
��ý�� ��ý����Ϣ���� ר����� �������� ��Ȼ���� ����
<
2017/2/14
������������������Ϊ���ĵ����ѧϰͨ��������ʽ�γ�ԭʼ���������Ա������Ȼ���ԡ������ͼ�����Ӿ�������ȡ����������չ�����ǣ���һ����ʽ���̼�ʽ��ѧϰ������Ҫ��̽��ʽ��ֱ��ǣ����������ʽѧϰ����Ծ�����߱���ѧϰ��ѧϰ(learning to learn)���������γɽ�����ǿ��������������֪ʶ������ģ�ͺͷ�����
����LCS��LS-SVM�Ķ������ǿ��ѧϰ
ѧϰ������ Эͬ��С����֧�������� ǿ��ѧϰ ������� Learning Classifier System LS-SVM Reinforcement Learning Multi-Robot
<
2014/6/20
���������һ��LCS��LS-SVM���ϵĶ������ǿ��ѧϰ������LS-SVM��õ�����ѧϰ������ΪLCS�ij�ʼ����LCSͨ���뻷���Ľ������ܸ��췢��ָ���������ǿ��ѧϰ�Ĺ���Ϊǿ��ѧϰϵͳ�Ķ���ѡ���ṩʵʱ����̬�ķ�����ʹ�������������ѧϰ���Э�������Ų��ԡ��㷨�ķ����ͷ�������������ѧϰ�ռ��ѧϰ�ٶ���������ѧϰЧ����ȷ��������õ��ܴ�ĸ��ơ�This paper presents ...
ǿ��ѧϰ����������˻�������ѧϰ�е�Ӧ��
ǿ��ѧϰ ������������� ��Ϊѧϰ
<
2009/10/22
��Ҫ�о���ǿ��ѧϰ�㷨�����ڻ��������������������ѧϰ�����е�Ӧ�ã�ǿ��ѧϰ��״̬�ռ�
�Ͷ����ռ����������������������ѧϰ���ٶȹ����������������������һ���⣬����˻���T-S ģ��ģ��
�������ǿ��ѧϰ�������ܹ���Ч��ʵ��ǿ��ѧϰ״̬�ռ䵽�����ռ��ӳ�䣮���⣬ʹ�������ǿ��ѧϰ��
���������������˵ļ����������о����ڲ���Ҫר��֪ʶ�ͻ���ģ������»����˵���Ϊѧϰ���⣮���ͨ
...
ǿ��ѧϰ���ƶ����������������е�Ӧ��
ǿ��ѧϰ �������� ������
<
2009/7/1
�������ƶ������˳��õ����������㷨������ȱ��,�ڴ˻����������ǿ��ѧϰ������������ǿ��ѧϰ�㷨��ԭ��,��ʵ���������������������⡣����˻����ϰ���̽�������Ϣ�Ļ�������������ǿ��ѧϰ����,������ѧϰ�㷨�и�Ҫ�ص���ѧģ�͡���������֤,�㷨��ȷ��Ч,�������õ������Ժͷ���������
����ǿ��ѧϰ��δ֪�����������Э���Ѽ�
�������ϵͳ ǿ��ѧϰ Э��
<
2009/6/26
��Զ������Э�������Ѽ�������ѧϰ�ռ��ѧϰ�ٶ��������⣬����˴���������˫��ǿ��ѧϰ�㷨����ǿ��ѧϰ�㷨�����ܹ�ʵ�ֵͲ�״̬-�����Ե�ѧϰ�������ܹ�ʵ�ָ߲�����-��Ϊ�Ե�ѧϰ���߲�����-��Ϊ�Ե�ѧϰ������ѧϰ�ռ����ϱ�ը����������Ӧ��ǿ���˻����˼�Э��ѧϰ������������ʵ����˵�����᷽���ӿ���ѧϰ�ٶȣ�������δ֪�����¶�����˸����Ѽ������Ҫ��
���ڶ�Agentǿ��ѧϰ�Ķ�վ��CSPSϵͳ��Э��Look-ahead����
���ʹ����������ӹ�վ Look-ahead���� ��Agentǿ��ѧϰ ���ܺ���
<
2010/3/1
�о���վ�㴫�ʹ����������ӹ�վ(Conveyor-serviced production station, CSPS)ϵͳ�����ſ�������, ���Ż�Ŀ����ͨ������ѡ��ÿ��CSPS��Look-ahead���Ʋ���, ʵ������ϵͳ�Ĺ������������.�������ȸ��ݶ�Agentϵͳ�ķ�Ӧ��ɢ˼��, ��ÿ��Agent��ԭʼ���ܺ������иĽ�, �����˾�����ɢ���ܵľ�����Ϣ������(ԭʼ������з�Ӧ����); ��������...
��������ƽ����ǿ��ѧϰ���������㷨
�Զ����Ƽ��� ǿ��ѧϰ ����ƽ��
<
2009/2/24
�����һ�ֻ�����С����ƽ����ǿ��ѧϰ�㷨�����ڽ�������ռ���ǿ��ѧϰ�������Ƶķ����������⡣���㷨�����ݶ��½���������ѹ��ӳ��ԭ����ͨ����������ƽ������Ϊֵ�������Ƶ����ܺ���������ֵ�������Ƶĵ�������ת��Ϊһ�������ڲ�����Ĺ��̡����㷨����ǿ��ѧϰ�㷨�ı����⪲Mountain Car�����������֤����������֤���㷨����Ч�ĺͿ��еģ����ҿ��Կ����������ȶ�ֵ��
����ǿ��ѧϰ�����ܻ����˱��������о�
ǿ��ѧϰ ���ܻ����� ����
<
2008/7/18
���IJ���ǿ��ѧϰ����ʵ�������ܻ����˵ı�����Ϊѧϰ���������Ƚ�����ǿ��ѧϰ
ԭ���������˲���������ʵ��ǿ��ѧϰϵͳ�ķ�����Ȼ��Ծ���ǿ��ѧϰ���Ƶ����ܻ���
�˱�����Ϊѧϰϵͳ�����˷���ʵ�飬���Է����������˷�����
�й��о����������а�-��
- ���ڼ���...
�й�ѧ���ڿ����а�-��
- ���ڼ���...
�����ѧ���л������а�-��
- ���ڼ���...
�й���ѧ���а�-��
- ���ڼ���...
�ˡ���-ƪ
- ���ڼ���...
�Ρ���-ƪ
- ���ڼ���...
��������-ƪ
- ���ڼ���...
�������� -ƪ
- ���ڼ���...
֪ʶҪ��-ƪ
- ���ڼ���...
���ʶ�̬-ƪ
- ���ڼ���...
��������-ƪ
- ���ڼ���...
ѧ��ָ��-ƪ
- ���ڼ���...
ѧ��վ��-ƪ
- ���ڼ���...